Policy Research Institute Trends in medical record integration as seen in the case of COVID-19
Medical information managed at medical institutions and biobanks is beginning to be used to improve the quality of medical care and in the research and development of pharmaceuticals by integrating and analyzing information from multiple institutions. In particular, the outbreak of new coronavirus infection (COVID-19) has further increased the demand for the use of medical information from a public health perspective. This section discusses a mechanism for efficiently utilizing medical information in the pharmaceutical industry, based on examples of actual use in COVID-19.
Introduction
In recent years, the pharmaceutical industry has been actively considering the use of medical records and other information obtained in actual clinical practice for research and development and epidemiological studies. When using such information, there are many situations where it is desirable to integrate information collected at multiple medical institutions for analysis, rather than using only information obtained at a single medical institution, in order to secure the number of cases to improve the estimation accuracy of the analysis and to improve the external validity of the results. On the one hand, the information collected at multiple medical institutions should be integrated for analysis. On the other hand, providing patient information outside of a medical institution for the purpose of conducting an integrated analysis is not permitted under the Personal Information Protection Law in Japan, the Health Insurance Portability and Accountability Act (HIPAA) in the U.S., or other laws in various countries, It is not easy to integrate individual medical information across medical institutions. In response to this problem, the Next Generation Healthcare Infrastructure Act has been enforced in Japan, and measures have been taken to promote the use of medical information, such as the provision of personal information to authorized providers through an opt-out process. However, many barriers remain, such as the burden on medical institutions when notifying the person in question and the cooperation among certified providers. Although discussions on legal measures are often the focus of attention to resolve these issues, recently, various information integration approaches have been developed from a technical perspective to reduce the risk of personal information leakage while maintaining the benefits gained from the research use of medical records, and studies are being conducted to put these approaches into practical use. This paper discusses the various approaches in practice. This paper discusses how medical information should be integrated, using the integration of electronic health records (EHR) centered on electronic medical records as a case study in COVID-19, where a variety of approaches have been implemented.
Methods of Integrating Medical Information
Research use of databases integrating information held by medical institutions is being studied worldwide for a wide variety of diseases, including those led by national governments and those aiming at cross-border integration. Integration of information is achieved mainly through the following three methods ( Figure 1 ).
Figure 1 Types of information integration methods 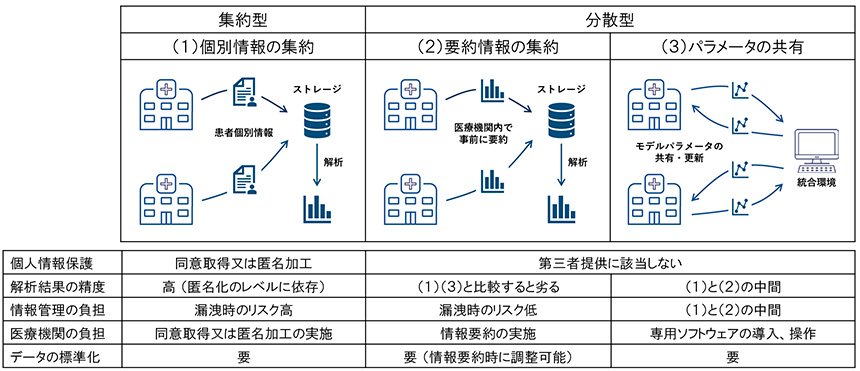
(1) Consolidation of individual case information
Methods in which patient-specific information held by each medical institution is made accessible from a central integrated environment, or in which replicated patient-specific information is consolidated in central storage and then analyzed in the integrated environment.
(2) Aggregation of information summarized at medical institutions
A method in which each medical institution summarizes personal information to a granularity that can be provided to external parties for regulatory purposes, consolidates only the summarized information in central storage, and then performs the analysis in an integrated environment.
(3) Sharing of analysis parameters performed at medical institutions
This method is used to construct prediction and classification models by updating the parameters of the model at each medical institution using the information in its possession, consolidating the parameters in a central integrated environment, and returning the information obtained from the consolidated parameters to each medical institution to repeat the parameter update process, A framework called federated learning or split learning has been devised to build a shared model adjusted using data from all medical institutions.
Since statistical processing commonly used basically assumes that all information is stored in a single storage location, the most suitable method of integrating information for analysis is the method (1), which consolidates information on individual cases in a single location. In most cases, this method falls under the category of providing personal information to a third party, and therefore, it is required to obtain consent from the information provider or to anonymously process the provided information. From the perspective of analysis alone, it is desirable to obtain consent for research use from all patients. However, given the fact that there are requests to relax the requirements for opt-out as required by the Next Generation Medical Infrastructure Act, it can be inferred that obtaining consent will be a significant burden for medical institutions. In addition, it is necessary to consider the impact on the analysis results of patient selection bias caused by the presence or absence of consent. From the viewpoint of information management, the risk of information leakage increases and the cost of information management increases because personal information or anonymized processed information must be handled directly from the viewpoint of a third party who receives the information as a third party. In addition, anonymized processed information has problems such as dealing with re-identification risk and loss of information due to anonymization. Thus, method (1), which aggregates information on individual cases, has several concerns in terms of personal information protection, but is still one of the most widely used data integration methods because it is the simplest in terms of structure and has many advantages in terms of analysis.
Along with the aggregation of information on individual cases, another widely used method is (2), in which information is summarized within a medical institution and the results of the summary are consolidated in a central storage. The simplest example is the fixed-point survey of seasonal influenza epidemics conducted by the Ministry of Health, Labor and Welfare. In the fixed-point survey, the number of patients is tabulated by gender and age group at each medical institution and submitted to the public health center, and the number of infected patients is recalculated at the prefectural level based on the results of each medical institution's total. Thus, if the information required is aggregate values such as the number of patients, the burden of analysis at medical institutions will increase, but there is no need to integrate information on individual cases, and information management will be relatively easy.
Finally, there is a method to create prediction and classification models without sharing information on individual cases by repeating the sharing of analysis parameters described in (3). This method has been the subject of much research for practical application, starting with a framework called Federated learning, which was published in 2016. (It is a derivative of the method of aggregating summary information in (2) and, similarly, does not require the provision of patient-specific information to a third party. It is possible to construct a model with higher external validity than when building a model at a single medical institution.
Examples of information integration methods in COVID-19
In order to understand the trend of integration methods of medical information, we will organize the characteristics of integration methods and how to deal with personal information protection based on the integration methods of EHRs in COVID-19, where various databases have been created all over the world. (As an example of (1) the method of aggregating information on individual cases, a database created with the assistance of government agencies in the United States and the United Kingdom (England), (2) the method of aggregating summarized information, the largest consortium of international EHR data in COVID-19, and (3) the method of sharing analysis parameters. (3) a study conducted by a medical institution at Harvard Medical School and a private company as an example of how to share the analysis parameters, respectively.
(1)-1 National COVID Cohort Collaborative (N3C)
An integrated database of EHRs for COVID-19 patients was established for research purposes in a project led by the National Center for Advanced Translational Science (NCATS), one of the research institutes of the National Institutes of Health in the United States. The database contains information on more than 6.4 million COVID-19 patients collected from more than 50 U.S. medical institutions (as of November 2021*1). The 18 identifiers to be removed under HIPAA (name, address, date, telephone number, fax number, email address, and social security number) are listed in the database, fax numbers, email addresses, social security numbers, medical record numbers, insurance numbers, account numbers, various license numbers, vehicle numbers, device identification numbers, URLs, IP addresses, biometric identifiers, personal photographs, and other unique identifiers), N3C has address information (zip codes) and date information for pandemic tracking purposes. and date information. Therefore, the security level of the data set provided is classified according to the purpose of analysis, and depending on the level, additional measures are taken, such as approval by the investigational review board (IRB) and access restrictions from institutions outside of Japan ( Table 1 ). In terms of information protection, technical measures have also been taken: access to the data is restricted within an analysis platform provided on the Gov-Cloud that meets the US government's definition of requirements, and all access to information and history of output of results is maintained centrally.
-
1Pfaff, Emily R., et al. Synergies between centralized and federated approaches to data quality: a report from the national COVID cohort collaborative.
Journal of the American Medical Informatics Association, 2022, 29.4: 609-618.
Table 1 Types of N3C data
 Source: abridged from the following paper
Source: abridged from the following paper
Haendel, Melissa A., et al. The National COVID Cohort Collaborative (N3C): rationale, design, infrastructure,
and deployment. Journal of the American Medical Informatics Association, 2021, 28.3: 427-443.
(1)-2 OpenSAFELY
The EHR analytics platform, developed under the auspices of the National Health Service (NHS England) and led by the University of Oxford, was built in the wake of the COVID-19 epidemic. Patient records from electronic health record vendors are provided, including information on approximately 58 million patients in the UK, including non-COVID-19 patients (as of October 2021*2 ). The UK has issued a notice of exception for COVID-19 research using patient information. When data is aggregated, consent for research use is not obtained from patients, and the information collected is subject to the EU General Data Protection Regulation (GDPR) and the Data Protection Act (DPA), The information collected is protected in accordance with the EU General Data Protection Regulation (GDPR) and the Data Protection Act, and pseudonymized using a hash function .3 The technical aspects of information protection are similar to those of N3C but a further feature is that the structure makes it impossible to access the actual data, even for researchers who have been authorized to access the data. This is achieved by using container technology, code management systems, etc., so that researchers can obtain output without ever viewing the data. The source code is also publicly available on GitHub, and the system is designed in an advanced manner to protect personal information, including from the perspective of ensuring transparency of analysis contents.
-
2Walker, Alex J., et al. Clinical coding of long COVID in English primary care: a federated analysis of 58 million patient records in situ using OpenSAFELY. British Journal of General Practice, 2021, 71.712: e806-e814.
-
3UK Health Service (Control of Patient Information) Regulations 2002 (COPI),
https://web.archive.org/web/20200421171727/https://www.gov.uk/ government/publications/coronavirus-covid-19-notification-of-data-controllers-to-share-information
(2) Consortium for Clinical Characterization of COVID-19 by EHR (4CE)
It is an international consortium led by organizations that aim to share, integrate, and standardize medical data, including EHRs, and consists of 315 medical institutions in six countries. The database contains approximately 80,000 patient records (as of October 2021*4 ). Participating medical institutions perform the analysis within their organizations and manage the aggregate results in a central storage system. Consent for research use is not obtained from patients because the data provided outside the organization does not contain personal information. Participating medical institutions have adopted a standardized platform for medical data and manage information in a similar data structure, so that analysis can be completed simply by executing a common analysis script created centrally at each medical institution.
-
4Weber, Griffin M., et al. International changes in COVID-19 clinical trajectories across 315 hospitals and 6 countries: a retrospective cohort study. Journal of medical Internet research, 2021, 23.10: e31400.
(3) EXAM (EMR CXR AI Model) consortium
The study, whose results were published in September 2021, used approximately 16,000 patient records. As with method (2), consent for research use was not obtained from patients, as data provided outside the organization does not contain personal information. The integration methods (2) and (3), which do not involve the transfer of information on individual cases, have been adopted in many cases in projects consisting of multiple countries that involve cross-border transfer of information.
-
5Dayan, Ittai, et al. Federated learning for predicting clinical outcomes in patients with COVID-19. Nature medicine, 2021, 27.10: 1735-1743.
Table 2 provides an overview of the EHR integration cases presented in this paper.
Table 2 Examples of HER integration presented in this paper at
 Source: prepared by The Office of Pharmaceutical Industry Research
Source: prepared by The Office of Pharmaceutical Industry Research
Characteristics of the database in terms of results obtained
How information is integrated should be considered after the purpose for which the information is to be used has been clarified. However, since it takes several years to several decades to accumulate medical records, discussions on how to integrate information often precede the determination of the purpose of use, in order to have a long-term perspective and to make the same database applicable to a wide range of research. In this section, we turn back and discuss appropriate methods of integrating data according to the purpose of use.
The validity of analysis using EHRs has been debated from various perspectives, including the definition of outcomes, unmeasured confounding factors, and mechanisms of missing measurements, but this section proceeds on the assumption that the desired analysis can be performed when information on individual cases is integrated. The analyses conducted using the information obtained from the EHRs mentioned in this case study can be broadly categorized into the following three types.
| A. | Calculation of summary statistics |
| B. | Construction of classification and prediction models |
| C. | Comparison among treatments and drugs |
A. Calculation of summary statistics
In the COVID-19 case study, this applies to the aggregation of background information such as the number of positive PCR test results, the number of deaths, and the age and gender of the target patients. In this type of analysis, even when summarized information is aggregated, it is possible to obtain results with almost the same accuracy as when information on individual cases is aggregated. From the viewpoint of privacy protection, except in cases where consent has been obtained from the patient, when anonymized information is aggregated, it is generally processed to remove specific descriptions (e.g., k-anonymization) in order to reduce the risk of re-identification of information. In situations where this processing is necessary, the same processing is performed when information on individual cases is aggregated, so there is no difference in the impact on the results obtained by both sides. On the other hand, by providing the results of aggregation at medical institutions to outside organizations, it is possible to remove information on the relationship between variables on an individual basis, thereby reducing the risk of re-identification of individuals by combining multiple pieces of information. Thus, except for the burden required at the time of aggregation at each medical institution, the method of aggregating summary information has significant advantages over the method of aggregating information on individual cases, and a structure that does not aggregate personal information is desirable when calculating summary statistics. However, in the pharmaceutical industry, there are few issues that can be solved only with summary statistics, so the following items also need to be considered.
B. Construction of classification and prediction models
One of the most in-demand analyses using medical records is the construction of classification and prediction models. In the pharmaceutical industry, this is widely used not only to predict the effects of drugs, but also to adjust for confounding when assessing the risk of adverse events and to search for biomarkers. From the standpoint of analysis accuracy, it is most desirable to aggregate information on individual cases, but there are also many studies being conducted on analysis methods that approach the accuracy of aggregating information on individual cases while taking into consideration the protection of personal information. In this section, we focus on the construction of a model to predict the risk of severe disease and death in COVID-19, and introduce the approaches used in each data integration method.
(In the method (1), which aggregates information on individual cases, the researcher builds a model in an environment where the information is aggregated, thereby achieving the objective. The N3C in the U.S. and OpenSAFELY in the U.K., which serve as interfaces to patient records, have restrictions such as analysis in a specified environment and analysis in which actual data cannot be viewed, as mentioned above, but if the analysis environment is carefully designed, these are not major obstacles to achieving the objective. In a study using N3C data, a model was constructed to predict the severity of COVID-19 using patient background (age, gender, complications, etc.) and laboratory values*6. Similarly, OpenSAFELY is building models to predict mortality risk based on patient background and comorbidities*7.
On the other hand, when a model is constructed by aggregating only summarized information (2), it is difficult to use information from other medical institutions to adjust the model parameters. 4CE has constructed a model to predict mortality risk for COVID-19 using patient background and laboratory values, The model is validated at other medical institutions, and the results are integrated using meta-analysis methods . The models were validated at other medical institutions, and the results were integrated using meta-analysis methods to evaluate their external validity while organizing the characteristics of the models on a country-by-country and institution-by-institution basis ( Figure 2 ). Behind the implementation of such an approach is the fact that the parent body of 4CE is a consortium that aims to standardize EHR data, and the data were managed in advance using a common data format (Common Data Model, CDM), which is a major contribution to the success of this project. This method also detected that low albumin levels, low lymphocyte counts, etc. affect the prognosis of COVID-19.
-
6Bennett, Tellen D., et al. Clinical characterization and prediction of clinical severity of SARS-CoV-2 infection among US adults using data from the National COVID Cohort Collaborative. JAMA network open, 2021, 4.7: e2116901.
-
※7Williamson, Elizabeth J., et al. Factors associated with COVID-19-related death using OpenSAFELY. nature, 2020, 584.7821: 430-436.
-
8 *9Weber, Griffin M., et al. International comparisons of laboratory values from the 4CE collaborative to predict COVID-19 mortality. NPJ digital medicine, 2022, 5.1: 1-8.
Figure 2 Schematic of the analysis performed in 4CE
 Source: prepared by The Office of Pharmaceutical Industry Research
Source: prepared by The Office of Pharmaceutical Industry Research
(The meta-analysis introduced in the method of aggregating summarized information in (2) above has limitations in terms of maximizing the accuracy of the model because it is not possible to update the parameters of the model using information from multiple medical institutions. In the EXAM consortium study, prognosis (oxygen dosage required) was predicted from chest X-ray images in addition to background information and laboratory values, and models built using this method were compared to models built using the single information held by each medical institution, It is reported that the model constructed by this method is superior in accuracy for all medical institutions compared to the model constructed using the single information held by each medical institution.
C. Comparison among treatments and drugs
Clinical trials are usually conducted to test the efficacy and safety of a drug in comparison with other treatments. This is done by randomization and blinding to eliminate the influence of factors other than the intervention in the groups being compared. However, in database-based treatment comparisons, these measures are not possible, so the most important issue is to ensure comparability, mainly by adjusting for confounding. At present, there are few cases in which comparisons between treatments have been made without aggregating information on individual cases. Therefore, this section will not focus on the case in COVID-19, but will consider whether studies will be possible in the future without aggregating information on individual cases. Possible situations include cases where information on both groups to be compared exists in the same database, or where the database is used as a control group for a clinical study conducted with a single group (use as an external control group). Assuming that the most widely used method for adjusting for confounding factors is propensity score adjustment, if the data for both groups to be compared exist in the same database, it is theoretically possible to calculate a propensity score by using logistic regression or other methods as described in the section on constructing classification and prediction models. When performing cross-medical institution matching, the propensity score itself must be shared with a third party, and if we pay close attention to the risk of re-identification of personal information, it is desirable to consider avoiding sharing the propensity score with a third party who knows the parameters of its calculation, or adjusting it by weighting it using inverse probability, etc.
On the other hand, when used as an external control group, the information held by each medical institution will serve as a control for the information obtained in the clinical research, so the treatment groups to be compared will be completely separated by the data from the medical institution and the clinical research. In such a situation, it would be difficult with current technology to improve the accuracy of trend score estimation by updating parameters within each medical institution.
Outlook
From the viewpoint of convenience in analysis, it is desirable to manage information on individual cases in a centralized manner, but from the viewpoint of personal information protection and the development of corresponding technologies, the integration of information is moving worldwide in the direction of conducting analysis while keeping information on individual cases confidential. The N3C in the U.S., which is introduced in this paper, initially considered the option of not centrally managing information on individual cases, but decided against it at this time due to concerns about the complexity of the project*9. 9 Even when information on individual cases is required, the risk of information leakage can be mitigated by establishing a design that controls the data itself and the processing of analysis in the cloud environment. Centralized data management is also effective in terms of immediacy of information reflection, and it is hoped that the transfer of anonymized processed information and analysis conducted at on-site centers in Japan will gradually be converted to analysis on virtualized servers such as cloud computing. In addition, all of the cases introduced in this report, regardless of the method of integration of information, were made possible by the similarity of data formats using CDM, and it is necessary to continue to focus on the standardization of information in Japan. There is a trade-off between the accuracy of the results obtained from the database and the strength of the protection of personal information. As the range of analyses that can be performed without collecting information on individual cases is expanding, it is becoming more important to determine the best data integration method according to the purpose of the analysis and the accuracy required.
-
9 *9Haendel, Melissa A., et al. The National COVID Cohort Collaborative (N3C): rationale, design, infrastructure, and deployment. Medical Informatics Association, 2021, 28.3: 427-443.
( The Office of Pharmaceutical Industry Research Chief Researcher Norihiro Okada )